
Relative Entropy ( 상대 엔트로피 )

상대 엔트로피, 또는 쿨백-라이블러 거리(Kullback-Leibler distance)는 두 확률 질량 함수(PMFs), p(x)와 q(x) 사이의 차이를 측정하는 데 사용되는 개념이다
두 확률 분포 사이의 '거리'를 나타내는 한 방법으로 생각할 수 있다
다만, 수학적으로 정확한 '거리'의 정의를 충족시키지 않는다는 점에서 '거리'라는 용어는 조금 오해의 소지가 있다
그 이유는 상대 엔트로피가 비대칭적이기 때문이다
따라서 D(p||q) 와 D(q||p)는 서로 다른 값을 가진다
상대 엔트로피는 기본적으로 두 확률 분포 사이의 '정보 손실'을 측정한다
p(x)를 '실제' 분포, q(x)를 모델이나 가정에 의한 '근사' 분포라고 할 때, 상대 엔트로피는 이 근사가 얼마나 잘 되었는지를 나타냅니다.
즉, 실제 분포를 기반으로 예상되는 정보량에서 근사 분포를 사용했을 때 기대되는 정보량을 뺀 것이라고 할 수 있다
( 실제 분포에서 근사 분포를 나타내었을때 얼마나 차이가 적게 나면서 실제 분포의 값을 나타내었나 )
p를 정확히 알고 있음에도 불구하고 q를 사용하여 p를 설명하려고 할 때,
그 과정에서 발생하는 정보의 손실이나 오류의 정도를 수치화한다
비대칭성
D(p||q) != D(q||p) 이는 p에 대한 q의 근사와 q에 대한 p의 근사가 다른 값을 가질 수 있음을 의미한다
비음성성
D(p||q) >= 0이며, 이는 정보 이론의 기본 원리 중 하나인 깁스의 부등식에서 유래한다
상대 엔트로피가 0인 경우는 p(x) = q(x)인 모든 (x)에 대해서만 발생한다
해석
상대 엔트로피 값이 크다는 것은 두 분포 사이의 차이가 크다는 것을 의미한다
그러나 이 '거리'는 직관적인 거리의 개념과는 다르며,
상대 엔트로피가 일정한 값을 갖는다고 해서 두 분포 사이의 실제 '거리'가 같다고 말할 수는 없다
두 확률 분포 사이에서 발생할 수 있는 특수한 경우를 어떻게 처리할지에 대한 규칙
1. 0 log(0/0)
두 분포가 동일한 이벤트에서 0의 확률을 가지는 경우이며 일반적으로 이를 0으로 정의
왜냐하면 이 이벤트는 두 분포에서 발생하지 않기 때문에 상대 엔트로피에 기여하지 않는다
2. 0 log(0/q)
q 분포에서는 어떤 이벤트가 발생할 확률이 있는 반면, p 분포에서는 그 이벤트가 전혀 발생하지 않는 경우
이 경우 기여도가 0으로 간주된다
3. p log(p/0)
p 분포에서 어떤 이벤트가 발생할 확률이 있지만, q 에서는 그 이벤트가 발생할 확률이 전혀 없는 경우
이는 q 분포가 p 분포의 중요한 특성을 완전히 무시하고 있다는 것을 의미하며, 이 때문에 상대 엔트로피는 무한대로 간주된다
이는 극단적인 정보 손실을 나타내며, q가 p를 모델링하는데 있어서 완전히 부적합함을 의미한다
Mutual information

상호 정보량(Mutual Information, MI)은 두 확률변수 (X)와 (Y) 사이의 정보를 공유하는 정도를 측정하는 데 사용되는 정보 이론의 개념이다
상호 정보량은 두 변수가 얼마나 서로에 대한 정보를 포함하고 있는지,
즉, 한 변수를 알 때 다른 변수에 대해 얻을 수 있는 정보의 양을 나타낸다
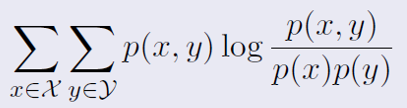
여기서 p(x, y)는 (X)와 (Y)의 결합 확률 분포이고, p(x)와 p(y)는 각각 (X)와 (Y)의 주변 확률 분포이다
이 식의 핵심은 p(x, y)가 p(x)p(y)와 비교하여 얼마나 다른지를 측정하는 것이다
만약 (X)와 (Y)가 독립적이라면, p(x, y) = p(x)p(y)가 되어 I(X; Y) = 0이 되며, 이는 두 변수 사이에 어떠한 정보도 공유되지 않음을 의미한다
증명 ( 해설 )
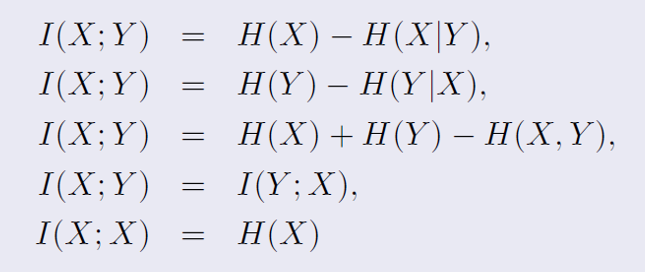
I(X;Y) = H(X) - H(X|Y)
이 식은 X의 엔트로피 H(X)에서 Y가 주어졌을 때 X의 조건부 엔트로피 H(X|Y)를 뺀 것과 같다는 것을 나타낸다
여기서, H(X)는 X의 불확실성의 총량을 나타내고, H(X|Y)는 Y의 값을 알고 있을 때 X의 남은 불확실성을 나타낸다
따라서, 이 차이는 Y를 알고 있을 때 X의 불확실성이 얼마나 감소하는지를 측정한다
이것이 바로 X와 Y 사이에 공유된 정보의 양이다
< H(X)가 얼마나 감소하는지에 따라서 X랑 Y가 어느정도로 정보를 공유하는지 알 수 있다 >
I(X;Y) = H(Y) - H(Y|X)
이 식은 Y의 엔트로피 H(Y)에서 X가 주어졌을 때 Y의 조건부 엔트로피 H(Y|X)를 뺀 것과 같다
이 역시 X를 알고 있을 때 Y의 불확실성이 얼마나 감소하는지를 나타낸다
상호 정보량은 대칭적이므로, I(X; Y)는 I(Y; X)와 같다
I(X;Y) = H(X) + H(Y) - H(X,Y)
이 식은 X와 Y의 개별 엔트로피의 합 H(X) + H(Y)에서 두 변수의 결합 엔트로피 H(X, Y)를 뺀 것과 같다
결합 엔트로피 H(X, Y)는 두 변수가 함께 발생하는 불확실성의 총량을 나타낸다
이 차이는 X와 Y가 각각 독립적으로 가지고 있는 정보에서 두 변수가 함께 가지고 있는 정보를 제외한 양,
즉 두 변수 사이에 공유되는 정보의 양을 나타낸다
I(X;Y) = I(Y;X)
상호 정보량의 대칭성을 나타내는 이 식은 X와 Y 사이의 정보 공유량은 Y와 X 사이의 정보 공유량과 같다는 것을 의미한다
이는 상호 정보량이 두 변수 사이의 관계를 나타내며, 이 관계는 방향성이 없음을 나타낸다.
I(X;X) = H(X)
변수 자신과의 상호 정보량은 그 변수의 엔트로피와 같다는 이 식은 변수가 자기 자신에 대해 가지고 있는 모든 정보를 포함하고 있음을 의미한다
자기 자신과의 상호 정보량은 변수가 가질 수 있는 정보의 최대량, 즉 그 변수의 불확실성의 총량과 같다
< X를 알고 있으면 X의 불확실성은 0 이 된다 >
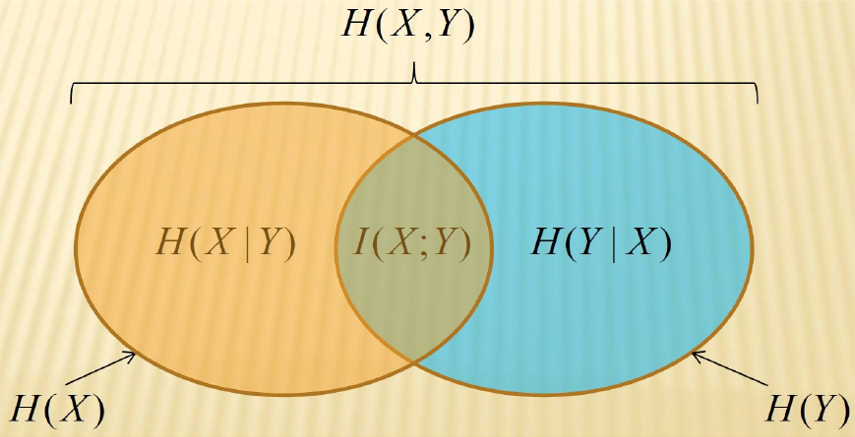
위 내용을 그림으로 나타내면 아래와 같다

'AI > AI정보이론' 카테고리의 다른 글
| [AI정보이론] Sufficient Statistics (0) | 2024.05.03 |
|---|---|
| [AI정보이론] Log Sum Inequality, Data-Processing Inequality (0) | 2024.05.03 |
| [AI정보이론] Jensen's Inequality (0) | 2024.05.03 |
| [AI정보이론] Chain Rule for Entropy (0) | 2024.05.03 |
| [AI정보이론] Entropy, Joint Entropy, Conditional Entropy (1) | 2024.05.03 |