
Convex Function ( 볼록함수 )
정보이론에서 볼록 함수(convex function) 개념은 엔트로피, 다이버전스 등 다양한 측정치를 분석할 때 중요한 역할을 한다
볼록 함수는 일반적으로 '위로 볼록한' 형태를 가지며, 함수의 두 점 사이에 그린 선분이 함수의 그래프 위에 위치하는 형태를 의미한다
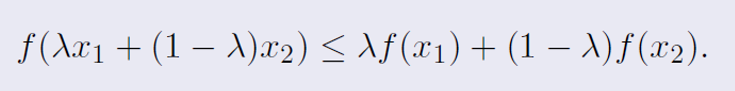
이 식에서, λ는 0과 1 사이의 가중치를 나타내며, x1과 x2는 구간 (a, b) 내의 임의의 두 점이다
이 조건은 볼록 함수의 정의를 제공하며, 본질적으로 x1과 x2를 연결하는 직선 위의 모든 점에 대해, 함수 f(x)의 값이 그 직선 아래에 위치하거나 그 위에 있음을 의미한다
만약 함수가 엄격하게 볼록(strictly convex)이라면, 동일한 조건이 적용되지만, 등호는 오직 λ=0 또는 λ=1일 때만 성립한다
엄격한 볼록성에서는 x1과 x2 사이의 모든 점들에 대해 f(x)의 값이 해당 점들을 연결하는 직선의 정확히 아래에 위치한다
이는 f(x)가 그 점들 사이에서 더욱 '급격하게' 커지거나 작아진다는 것을 의미한다
Concave Function ( 오목 함수 )
함수 f(x)가 오목 함수라는 것은 f(x)의 부호를 반전시킨 -f(x)가 볼록 함수가 됨을 의미한다
다시 말해, 오목 함수는 주어진 구간 내의 임의의 두 점을 연결하는 선분이 항상 함수의 그래프 아래에 있거나 그래프와 만나는 경우이다
볼록 함수와 오목 함수의 정의는 함수의 그래프와 임의의 두 점을 연결하는 선분사이의 위치 관계에 기반한다
볼록 함수에서는 이 선분이 항상 함수 그래프의 아래에 위치하는 반면, 오목 함수에서는 선분이 항상 함수 그래프의 위에 위치한다
이러한 성질은 함수의 형태와 최적화 문제를 다룰 때 중요한 의미를 가지며, 함수가 볼록 또는 오목인지를 파악하는 것은 함수의 최소값 또는 최대값을 찾는 문제를 해결하는 데 도움이 된다
2차 도함수
함수의 볼록성에 대한 좀 더 수학적이고 구체적인 기준을 제공하는 방법 중 하나는 함수의 두 번째 도함수(2차 도함수)를 검토하는 것이다
두 번째 도함수는 함수의 곡률(curvature)이나 변화율의 변화를 측정한다
이 기준은 볼록성을 판단하는 데 매우 유용하며, 간단하면서도 강력한 도구이다

함수 f가 어떤 구간에서 두 번째 도함수 f''(x)가 음수가 아닌(0 이상인) 경우, 함수 f는 그 구간에서 볼록 함수이다
수학적으로 표현하면, 구간 I 내의 모든 x에 대해, 만약 f''(x) >= 0 이면, 함수 f는 구간 I에서 볼록하다고 할 수 있다
이는 함수의 기울기가 그 구간에서 감소하지 않음을 의미한다
즉, 함수는 해당 구간에서 '위로 볼록한' 형태를 가지며, 두 점을 잇는 선분은 항상 함수의 그래프 아래에 위치하게 된다
Jensen's Inequalilty
젠센 부등식(Jensen's Inequality)은 볼록 함수와 확률 변수에 관한 중요한 부등식이다
이 부등식은 기대값, 볼록성, 그리고 확률 변수의 분포 사이의 관계를 설명한다

함수 f가 볼록 함수이고, X가 어떤 확률 변수일 때 젠센 부등식은 위와 같이 표현된다
여기서 E[X]는 확률 변수 X의 기대값이며, E[f(X)]는 확률 변수 X에 함수 f를 적용한 후의 기대값이다
이 부등식은 f가 볼록 함수일 경우에만 성립하며, 이는 확률 변수의 변동이 함수를 통과하면서 증가함을 나타낸다
기대값(expectation 또는 expected value)은 확률 변수의 평균적인 값이며, 확률적인 현상에서 어떤 결과가 일어날 것으로 예상되는 평균적인 수치를 의미한다
기대값은 확률 변수가 취할 수 있는 각각의 값과 그 값이 발생할 확률을 고려하여 계산된다
이는 확률적인 상황에서의 '평균'과 유사한 개념이지만, 모든 가능한 결과를 그 발생 확률에 따라 가중하여 계산한 값이다
볼록 함수
확률 변수의 기대값에 함수를 적용한 값은, 함수에 확률 변수를 적용한 후의 기대값보다 항상 작거나 같다는 것을 의미한다
이는 볼록 함수의 성질과 관련이 있으며, 볼록 함수의 그래프는 항상 선분으로 연결된 점들 아래에 위치한다는 사실에서 유래한다
엄격하게 볼록
젠센 부등식에서 등호가 성립한다면, 이는 X = E[X]가 확률 1로 성립함을 의미한다
즉, 확률 변수 X는 거의 확실하게 상수값을 가진다
엄격한 볼록성은 함수가 두 점 사이의 어떤 점에서도 해당 점들을 잇는 선분 아래에 위치한다는 것을 의미하는데,
등호가 성립한다는 것은 확률 변수의 모든 값이 그 기대값과 동일하다는 것을 의미하므로, 확률 변수가 상수값을 가진다
젠센 부등식의 의미
젠센 부등식은 확률 변수의 변동성이 볼록 함수를 통과할 때 증가한다는 것을 나타낸다
이는 변동성이 있는 시스템이나 프로세스에서 평균적인 성능이나 결과를 추정할 때 중요한 함의를 가진다
예를 들어, 투자의 기대 수익률을 계산할 때 제이슨 부등식은 높은 변동성이 기대 수익률에 미치는 영향을 평가하는 데 도움을 줄 수 있다
Information Inequality
2개의 PMF인 p(x), q(x)가 x 전체 범위인경우
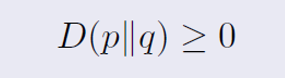
확률 질량 함수는 이산 확률 변수의 확률 분포를 나타내는 함수이다
그리고 D(p||q) >= 0은 두 확률 분포 p(x)와 q(x) 사이의 쿨백-라이블러 발산(KL divergence)를 나타내며,
이는 두 분포의 차이를 측정하는 데 사용된다
두 확률 분포 p(x)와 q(x) 사이의 비대칭적인 차이를 측정하는 방법으로 쿨백-라이블러 발산(KL divergence)가 사용되며,
비음성성이다
비음성성(Non-negativity) : D(p||q) >= 0
이는 정보 이론에서의 정보 부등식에 의해 보장되므로 두 분포가 완전히 동일할 때만 D(p||q) = 0이 된다
등식의 조건 : D(p||q) = 0이 성립하는 경우는 p(x) = q(x)가 모든 (x)에 대해 참일 때이다
이는 두 확률 분포가 서로 동일할 경우에만 KL 발산이 0이 된다는 것을 의미한다
증명
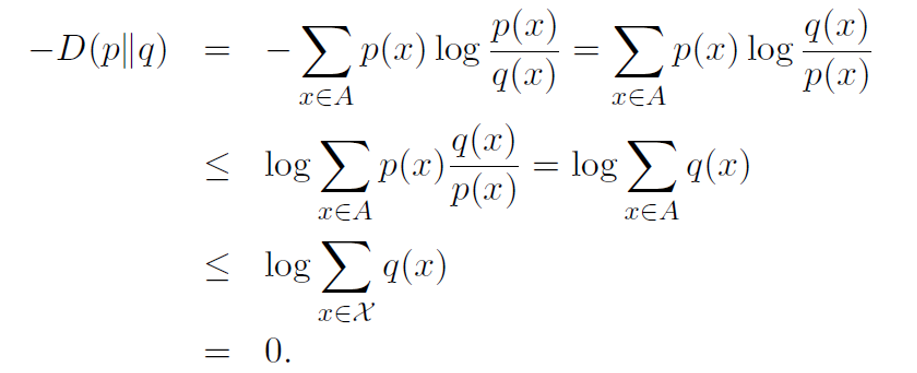
A = {x : p(x) > 0}를 p(x)의 지지 집합으로 정의한다
상대 엔트로피 D(p||q)의 정의에 따라 p(x)나 q(x)가 0이 될 수 있으므로,
0에 대한 로그의 정의 문제를 피하기 위해 합산은 p(x) > 0인 x에 대해서만 수행된다
그리고 로그의 성질에 의해 a = 1 일 경우에만 등호가 성립된다
상대 엔트로피의 식을 그대로 가져오면 마이너스 부등호에 의해서 log함수의 p(x), q(x)의 위치가 바뀐다
그리고 이 값은 log를 앞으로 빼낸 값보다 작다
최종 계산결과 log 안의 값을 다 더하면 0이 된다
따라서 D(p||q) >= 0 을 이용하여 아래의 식들도 증명된다
Mutual Information
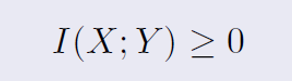
X, Y의 정보량이며 X, Y가 독립이면 0이 된다
조건부 확률 분포 p(y|x)와 q(y|x) 사이의 KL 발산

이 식은 두 조건부 확률 분포 p(y|x)와 q(y|x) 사이의 KL 발산이 항상 0 이상이며,
두 분포가 모든 y와 x에 대해 동일할 때만 0이 됨을 의미한다
조건부 상호 정보량 I(X;Y|Z)
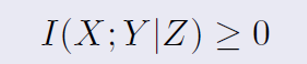
건부 상호 정보량 I(X;Y|Z)는 두 확률변수 X와 Y가 주어진 세 번째 변수 Z에 대한 조건 하에서 서로 얼마나 많은 정보를 공유하고 있는지를 측정한다
I(X;Y|Z) >= 0이며, 이 값이 0인 경우는 X와 Y가 Z에 대해 조건부 독립일 때, 그리고 그 때에만 발생한다
I(X;Y|Z) = 0은 다음과 같이 표현될 수 있습니다 : P(x,y|z) = P(x|z)P(y|z)
이 조건은 X와 Y의 결합 분포가 Z에 대한 각 변수의 조건부 분포의 곱과 같을 때 성립한다
이것은 Z를 알고 있을 때 X와 Y가 서로 독립임을 의미한다
I(X;Y|Z) >= 0의 증명은 KL 발산의 비음수성에 기반한다
조건부 상호 정보량은 조건부 확률 분포 사이의 KL 발산으로 표현될 수 있으며, KL 발산은 항상 0 이상이다
P(x,y|z) = P(x|z)P(y|z)에서 각 z에 대해 0 이상이다
I(X;Y|Z) = 0이 0이면 P(x,y|z) = P(x|z)P(y|z) = 0 인 모든 z에 대해 X와 Y가 Z에 대해 조건부 독립임을 의미한다
Maximum Entropy Distribution ( 최대 엔트로피 )

최대 엔트로피 원리는 주어진 제약 조건을 만족하는 확률 분포 중에서 가장 '무정보성'(즉, 엔트로피가 최대인)을 갖는 분포를 선택하는 원리이다
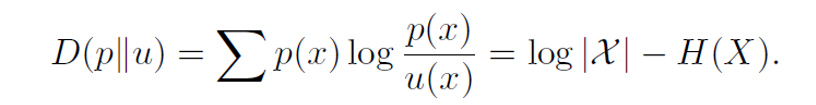
u(x) = 1/|χ| 라고 할때 위의 식이 정의된다
p(x) log p(x)는 H(X)가 된다

그래서 비음성성에 의해 위 식도 정의된다
Independence Bound on Entropy ( 엔트로피의 상한 )
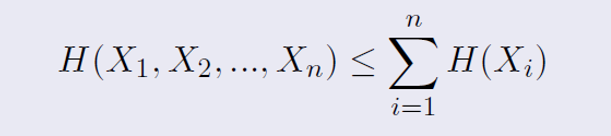
독립성에 대한 엔트로피의 상한(Independence Bound on Entropy)은 여러 확률변수들이 서로 독립일 경우,
이들의 결합 엔트로피가 각 확률변수의 엔트로피 합보다 작거나 같다는 원칙을 나타낸다
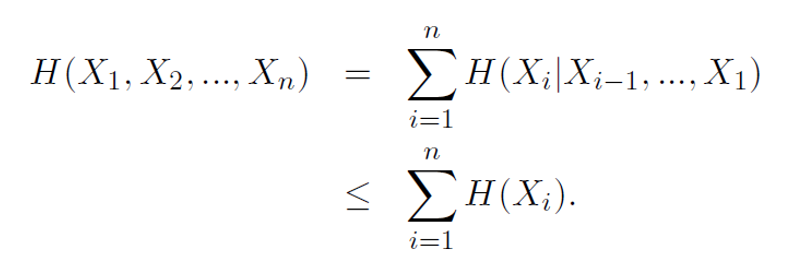
Chain Rule을 이용하여 X(i-1), ..., X1 부분을 Z라고 할 경우
H(X|Z) <= H(X) 이므로 위 식이 정의된다
Conditional Entropy

조건부 엔트로피 H(X|Y)는 이미 확률변수 Y의 결과를 알고 있을 때, 확률변수 X의 불확실성을 측정한다
다시 말해, Y의 값이 주어졌을 때 X의 불확실성의 평균을 나타낸다
이 부등식은 조건부 엔트로피 H(X|Y)가 항상 X의 엔트로피 H(X)보다 작거나 같다는 것을 의미한다
이는 Y의 추가적인 정보가 X에 대한 불확실성을 줄일 수 있음을 나타낸다
다시 말해, Y에 대한 정보가 X에 대한 정보를 어느 정도 제공하기 때문에, Y를 알고 있을 때 X의 불확실성이 줄어든다
등호가 성립하는 경우는 X와 Y가 독립일 때이다
X와 Y가 독립이라면, Y의 값에 관계없이 X의 분포가 변하지 않는다
즉, Y의 정보가 X의 불확실성을 줄이는 데 아무런 영향을 미치지 않는다
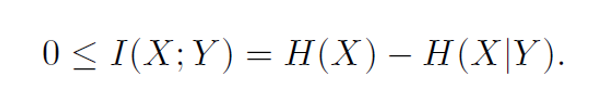
H(X)는 X의 엔트로피이며, H(X|Y)는 Y가 주어졌을 때 X의 조건부 엔트로피이다
이 공식은 X의 원래 엔트로피에서 Y를 알고 있을 때 X의 불확실성이 얼마나 감소하는지를 빼서 계산한다
즉, Y의 정보가 X에 대해 얼마나 많은 추가 정보를 제공하는지를 나타낸다
0 <= I(X;Y)는 KL Divergence가 0 이상임을 이용해서 정의할 수 있다


'AI > AI정보이론' 카테고리의 다른 글
| [AI정보이론] Sufficient Statistics (0) | 2024.05.03 |
|---|---|
| [AI정보이론] Log Sum Inequality, Data-Processing Inequality (0) | 2024.05.03 |
| [AI정보이론] Chain Rule for Entropy (0) | 2024.05.03 |
| [AI정보이론] Relative Entropy, Mutual information (0) | 2024.05.03 |
| [AI정보이론] Entropy, Joint Entropy, Conditional Entropy (1) | 2024.05.03 |