
기댓값 길이 L(C)
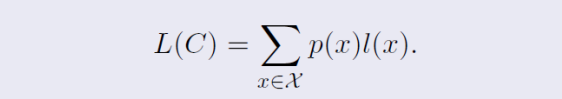
기댓값 길이 L(C)는 p(x)와 l(x)의 곱들의 합으로 구할 수 있다
여기서 l(x)는 코드워드의 길이를 나타내고, 코드워드는 C(x)로 라고 한다
위 방식대로 계산하면 전체 코드의 평균 길이를 계산할 수 있다
예를 들어, 확률 변수 ( X )가 값 1, 2, 3을 가질 수 있고,
각 값의 확률이 각각 p(1) = 0.5, p(2) = 0.3, p(3) = 0.2이며,
대응하는 코드워드의 길이가 l(1) = 2, l(2) = 3 , l(3) = 1 일 때,
기댓값 길이 L(C) 는 아래와 같이 계산된다
L(C) = (0.5 * 2) + (0.3 * 3) + (0.2 * 1) = 1 + 0.9 + 0.2 = 2.1
X가 Random Variable이고 codeword가 아래와 같다고 할 경우 H(X)와 L(C)는??
Pr(X = 1) = 1/2, C(1) = 0
Pr(X = 2) = 1/4, C(2) = 10
Pr(X = 3) = 1/8, C(3) = 110
Pr(X = 4) = 1/8, C(4) = 111
H(X)는 -sum ( p(x) * log2 p(x) ) 이므로 1.75 이다
L(C)는 (1/2 * 1) + (1/4 * 2) + (1/8 * 3) + (1/8 * 3) = 1.75 이다
추가적으로 0110111100110은 134213으로 해석이 가능하다
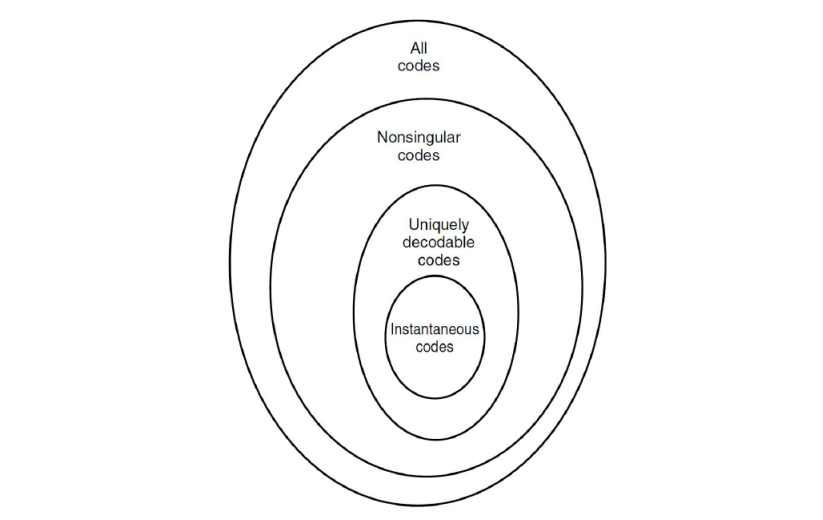
코드를 전체적으로 분류하자면 위와 같이 나타나진다

그리고 각각의 분류에 맞는 예시는 위와 같다

Nonsingular 같은 경우 단일 값의 전송에는 충분하지만 나머지의 경우 그렇지 못하다
구분자를 추가하면 각 코드워드가 어디서 끝나고 다음 코드워드가 어디서 시작하는지 정확하게 판별가능해진다

Uniquely Decodable 같은 경우 C(x1)C(x2)...C(xn)은 각 코드워드의 연결을 나타낸다
즉, 서로 다른 입력 문자열의 코드워드 연결이 서로 다른 결과를 가져온다
코드 C의 확장 C*가 유일하게 해독 가능하려면, C(x1x2) ≠ C(y1y2)일 때 x1x2 ≠ y1y2이어야 한다
그래서 유일하게 해독이 가능하다
Kraft Inequality
Kraft Inequality는 접두사 코드를 설계할 때 중요한 개념이다
주어진 소스를 설명하기 위한 최소 기대 길이의 즉시 해독 가능한 코드를 구성할 수 있다

크래프트 부등식은 위와 같다
여기서 li는 각 코드워드의 길이이고, D는 사용되는 알파벳의 크기이다
즉, 각 코드워드의 길이의 역수의 합이 1보다 작거나 같아야 한다는것을 나타낸다
D-ary tree를 사용하며 2진 트리에서 접두사 코드를 구성한다고 가정해보면
- 코드워드 '0'을 선택하면, '0'의 자손인 '00', '01' 등은 사용할 수 없다
- 코드워드 '10'을 선택하면, '10'의 자손인 '100', '101' 등은 사용할 수 없다
위와 같은 예시가 있다
따라서 크래프트 부등식은 접두사 코드를 설계할 때 필수적인 조건을 제공하며,
이를 통해 주어진 소스를 설명하기위한 최소 기대 길이의 코드를 구성할 수 있다
D-ary tree를 이용한 코드 구성 방법을 통해 접두사 조건을 만족하는 코드를 만들 수 있고,
이는 데이터 전송 및 압축에서 중요한 역할을 한다
'AI > AI정보이론' 카테고리의 다른 글
| [AI정보이론] Channel Capacity (0) | 2024.06.16 |
|---|---|
| [AI정보이론] Data Compression - Huffman Code (0) | 2024.05.28 |
| [AI정보이론] Fano's Inequality (0) | 2024.05.03 |
| [AI정보이론] Sufficient Statistics (0) | 2024.05.03 |
| [AI정보이론] Log Sum Inequality, Data-Processing Inequality (0) | 2024.05.03 |